CLAUDE.mdを書いてから数日、自分はずっと「なんか物足りない」という感覚があった。AIが応答してくれる。ちゃんと自社のことを覚えている。でも、何かが足りなかった。今振り返ると、あのとき足りなかったのは「ルール」だった。口調だけじゃなく、何をしてよくて何をしてはいけないか。憶測で動いていいのか止まるべきか。そういう判断基準を書いたファイルがなかった。書き始めてから初めて、Claude Codeが「うちのAI」になった感覚があった。今回はその話を書きます。
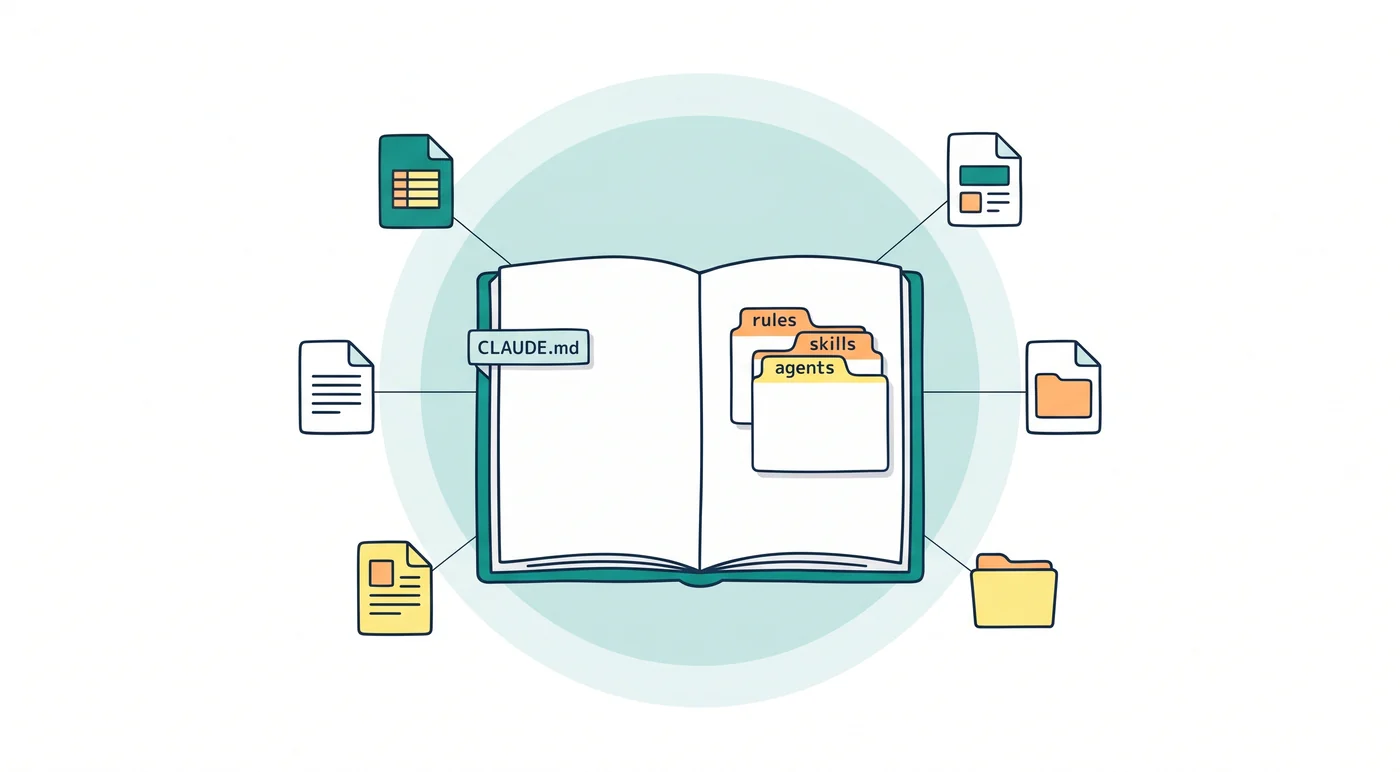

FlatWorksのルールファイル構造を全部見せる
最初に現状のファイル構造を見せてしまう。全部で4階層になっている。
$tree ~/.claude/
~/.claude/
├── CLAUDE.md # ユーザー指示。全プロジェクト共通の絶対ルール
├── rules/ # 個別ルールファイル群(CLAUDE.mdから @ で参照)
│ ├── persona.md # 口調・キャラクター定義
│ ├── language.md # 言語・文体の制約
│ ├── safety_quality.md # 安全・品質の基準
│ ├── ask_before_act.md # 憶測で進まない、確認してから動く
│ ├── secretary.md # 秘書AIの動作定義
│ └── ...(全33ファイル)
├── knowledge/ # 全案件共通の知識ベース
│ └── INDEX.md # 外部データ取得方法、MCPサーバー情報など
├── skills/ # 専門知識(トリガーで自動起動)
│ ├── hp-expertise/ # HP/LP評価の専門知識
│ └── sns-expertise/ # SNS投稿・分析の専門知識
├── agents/ # サブエージェント定義(部署AI)
│ ├── hp-director.md
│ ├── sns-director.md
│ └── ...
└── projects/ # プロジェクト固有の自動メモリ
└── flatworks/
└── memory/
├── MEMORY.md # 目次(最初の200行が読まれる)
├── project_*.md # プロジェクトの方針・経緯
├── feedback_*.md # 失敗事例・禁則事項
└── reference_*.md # 技術リファレンス・仕様メモ
2026年5月時点の Claude Code 公式仕様では、CLAUDE.md は「ユーザー指示(User)」「プロジェクト指示(Project)」「ローカル指示(Local)」「管理ポリシー(Managed)」の4スコープが用意されている。上の ~/.claude/CLAUDE.md はユーザー指示で、全プロジェクト共通だ。プロジェクト指示は ./.claude/CLAUDE.md に置く。読み込み優先度は「より具体的なスコープが優先」というルールで、Managed → Local → Project → User の順だ。(出典: Claude Code 公式ドキュメント — メモリ管理)
その下の rules/ が個別ルールのディレクトリで、今は33ファイル置いてある。これは全部を毎回読ませているわけではない。CLAUDE.md から必要なものだけ @rules/persona.md のように参照する構造になっている。
skills/ は Claude Code に追加された機能で、各スキルディレクトリに SKILL.md を置くと、内容に応じたトリガー条件で自動起動する。HP制作のキーワードが会話に出たら hp-expertise が起動する、という仕組みだ。常時ロードを避けて、必要な場面だけ専門知識を呼び出せる。
agents/ はサブエージェント(Subagents)の定義置き場だ。役割ごとに独立した人格・ルール・ツール権限を持った別エージェントを呼び出せる。FlatWorksでは「秘書」「HP事業部長」「SNS事業部長」など、複数の部署を定義している。
プロジェクト固有の記憶は projects/<プロジェクト名>/memory/ 以下に置く。これは Claude Code v2.1.59 で追加された「自動メモリ(Auto memory)」が読み込む場所だ。MEMORY.md がエントリポイントで、その200行までがセッション開始時に自動読み込みされる。project_*.md はそのプロジェクトの方針・背景・意思決定の経緯。feedback_*.md は失敗事例と禁則事項。reference_*.md は技術リファレンスやAPIの仕様メモ。役割によってファイル名を分けているのは、「次に作業するとき何を読めばいいか」をAIが判断しやすくするためだ。
この構造はゼロから設計したわけではなく、運用しながら「やっぱりここは分けた方がいい」「このファイル読ませすぎてる」という感覚で育てていった。今の形になるまでに3ヶ月くらいかかっている。
設計の3軸――階層・優先度・更新頻度
ルールファイルの構造を整理する上で、自分が意識するようになった3つの軸がある。
軸1:階層(user → project → session)
一番外側のユーザー指示(~/.claude/CLAUDE.md)は「どの仕事でも変わらないこと」だけ書く。口調、憶測で動かないこと、コードの全文を貼らないこと。これは顧客のHP制作でも、自社のブログ更新でも同じだ。
プロジェクト指示は「その仕事特有のこと」。電気工事業(仮名)のHPを担当しているなら、その業界の言い回し、顧客が嫌う表現、使うべき画像のトーン。これはほかの案件には必要ない情報だ。
セッション層は「今日この作業限定のこと」。毎回記憶するほどではないが、今日だけ守ってほしいこと。これはファイルに書くより、会話の最初に一言伝えればいい。
この階層を意識せずに全部をユーザー指示の CLAUDE.md に書いていた時期があった。電気工事業(仮名)の固有ルールと、自社の口調ルールと、その日の特別指示が同じファイルに混在していた。読ませる量が増えるにつれ、どこかが抜けたり混線したりするようになった。
軸2:優先度(絶対ルール vs 推奨 vs オンデマンド参照)
全部のルールに同じ重みをつけない、というのが運用してみて分かった教訓だ。
「絶対に守ること」は少数にする。本番環境を直接操作しない。APIキーをコードに書かない。個人情報を無断でAIに渡さない。これは絶対。
「推奨事項」はその次。こっちの書き方の方がいいよ、という程度のもの。AIが状況次第で判断していい範囲だ。
「オンデマンド参照」は必要な場面だけ読ませるもの。競合他社の比較記事を書くときだけ参照するルール、30分以上かかる処理を走らせるときだけ確認するゲート。毎回全部読ませる必要がない。
この分類をするまで、全ルールを毎回読み込もうとしていた。そうすると後述する CLAUDE.md 肥大化問題に直結する。
軸3:更新頻度(毎日変わるもの / めったに変わらないもの)
口調や基本的な安全規律はほとんど変わらない。一度書けば半年は触らなくていい。
一方、プロジェクトの方針は変わる。顧客から「やっぱりこのトーンやめたい」と言われたり、失敗した施策の教訓が出てきたりする。この情報は都度更新しないと、古い判断基準でAIが動き続ける。
更新頻度の高いものと低いものを同じファイルに書くと、管理が面倒になる。「よく更新するもの」だけを分けたファイルにしておくと、作業の摩擦が下がった。
やってみて分かった失敗例
ここが今回の本題だと思っている。うまくいった話よりも、やらかした話の方が参考になることが多いので、正直に書く。
失敗1:CLAUDE.md が肥大化して、AIが読まなくなった
最初の2ヶ月、とにかく CLAUDE.md に追記し続けた。口調のルール、安全規律、業界知識、顧客ごとの固有情報。「全部ここに書けばいい」という感覚でいた。
そのうちに気づいた。AIの応答がどこか薄くなった。守るべきはずのルールが守られないことが増えた。ファイルが長すぎて、後半に書いたことが実質読み飛ばされているような挙動だった。
これはAIの問題ではなくて、設計の問題だった。人間だって、100ページのマニュアルを毎日最初から読んで仕事する人はいない。「今の作業に関係あるところだけ参照する」構造にしないと機能しない。
解決策は2つだった。CLAUDE.md を「目次と絶対ルールだけ」に絞り込むこと。詳細は @rules/safety_quality.md のような参照先を示すだけにする。もう1つは、専門知識をスキル(Skills)として分離して、必要な場面でだけ読み込む仕組みにすること。「HP制作をしているとき」「SNS投稿を書いているとき」というトリガーで、該当の専門知識ファイルが起動する。常時全部ロードではなくなった。

さっきの電気工事業(仮名)さんのLP、コピーライティング規律守れてた?
確認したら、CTA文言が「お問い合わせ」のままだった。「無料で相談する」に変える指示がルールに書いてあったのに。CLAUDE.md後半の規律が読み込まれてなかったかも。ファイル分割を検討します。
失敗2:口調ぶれ。ペルソナがプロジェクトごとに違う顔を出した
秘書AIの口調は persona.md に定義してある。丁寧で正直、ちょっと抜けてるくらいが親しみやすい、という設計だ。
ところがプロジェクト固有のファイルにも「この顧客向けはもう少しかたくて」「このページはテンションを上げて」という記述を書いていた時期があった。すると秘書の口調が、会話の途中で変わることが起きた。前半はいつもの秘書、後半はビジネスライクなAI。同じセッション内で人格が揺れる。
これは顧客ごとのトーン指定を「出力するコンテンツのトーン」と「AIエージェント自身の口調」を混在して書いていたのが原因だった。AIエージェントの口調はユーザー指示で固定、顧客向けコンテンツのトーンはプロジェクト固有のファイルに分ける。この2つを分けてからは安定した。
失敗3:feedback_*.md と reference_*.md の内容が重複した
「電気工事業(仮名)の業界用語」を reference_denki.md に書いた。同時に、ある失敗事例の対策として「この業界では『低圧工事』は使わず『低圧電気工事』と書く」という教訓を feedback_terminology.md に書いた。同じことが2つのファイルに存在した。
どちらが新しいか、どちらが正しいか。更新が片方にしか反映されず、AIが古い情報で動くことがあった。
今は「技術仕様・業界情報は reference_*.md に集約」「失敗事例・禁則は feedback_*.md に集約」という切り分けを厳密にしている。似た内容があったら reference に書いて、feedback からは「reference を見ろ」とだけ書く。
失敗4:専門知識を毎セッション全文ロードしていた
HP制作の専門知識、SNS運用の専門知識、業種別の知識。これを全部 CLAUDE.md から読み込もうとしていた時期がある。
問題は2つ出た。1つは単純にファイルが重くなること。もう1つは「HP作業と関係ない知識」が読み込まれた状態でHP以外の作業をすると、ノイズになることがあった。
今はこれをスキル(Skills)という形に分離している。「HPやLPを作っている」「SNS投稿を書いている」というトリガーが検出されたとき、初めて該当の専門知識ファイルが起動する仕組みだ。常時全部ロードではなくなったので、各セッションで必要な知識だけが参照される状態になった。
これから始める人への最小セットアップ
「全部やろうとすると動けない」という罠がある。うちも最初からすべての設計を決めたわけではない。今の形は運用の積み重ねだ。だから「最初にこれだけ作れば動く」というセットを書いておく。
最初に書くべき5ファイル
1. ~/.claude/CLAUDE.md(ユーザー指示)
会社概要(事業内容・規模・業種)、絶対に守ってほしいこと(コードの全文を貼らない、わからないことは確認してから動く、等)、参照先のルールファイルへのリンク(@rules/persona.md 等)。最初は200〜300字で十分。長くしない。
2. ~/.claude/rules/persona.md
AIエージェントの口調・人格を定義する。ビジネスライクにするか、少し親しみやすくするか。「こういう言い方はNG」という例を2〜3個書くと効果的だった。定義が曖昧だと、セッションをまたぐたびに口調が変わる。
3. ~/.claude/rules/safety_quality.md
何をやってはいけないか。本番DBに直接触らない。顧客の個人情報を含むファイルをAIに渡さない。決定前に確認する。この3点だけでも最初は十分だ。
4. ~/.claude/projects/<案件名>/memory/project_<案件名>.md
その案件の背景・目的・判断基準を書く。「なぜこのサービスを作っているか」「ターゲットは誰か」「使ってはいけない表現はあるか」。1ページ以内で収める。
5. ~/.claude/projects/<案件名>/memory/MEMORY.md
目次ファイル。この案件に関連するファイルが何で、どこにあるかを書く。最初は4〜5行でいい。Claude Code はこのファイルの最初の200行をセッション開始時に自動で読み込むので、目次として使うとちょうどいい。
育て方の順序
1日目は上の5ファイルを作るだけ。完璧じゃなくていい。書いてみてから動かす。動かした後に「なんか違う」と感じたところを直す。
1週目は「今日ちょっと変だったな」と感じた場面を記録しておく。セッションの最後に5分だけ「今日うまくいかなかったこと」を feedback_*.md に書く習慣をつける。最初のフィードバックファイルは、失敗の記録だ。
1ヶ月目になると、自然と「ここのルールが足りない」「この知識を読ませ続ける必要はない」という感覚が出てくる。そのタイミングで構造を見直す。
急いで完成させようとしない方がいい。ルールファイルは「完成する」ものではなくて、「育てる」ものだと今は思っている。
それと、1つだけ最初に肝に銘じておいてほしいことがある。
「AIが思い通りに動かない」は、ほぼ設計の問題だった。
AIの能力の話ではなく、何を書いてどう読ませるか、の話だった。うちはそこを整理してから、ずっと使いやすくなった。
まとめ
ルールファイルは「設計の翻訳」だと思っている。
頭の中にある「うちのやり方」「うちの判断基準」「うちのトーン」を、AIが読める形に翻訳したものがルールファイルだ。翻訳しないと、どんなに高性能なAIも「汎用の道具」のまま終わる。
翻訳の精度が上がるほど、AIは「うちのことを知っている存在」に近づいていく。その感覚は、使っていくと少しずつ分かってくる。
1日でできるものじゃない。うちは今も書き続けている。でも、書いた分だけ手応えが変わる。そういうものだった。
よくある質問
ルールファイルって、CLAUDE.mdだけじゃダメなの?
CLAUDE.mdだけでも基本動作はします。ただし、口調・安全規律・業界知識・顧客固有情報を全てCLAUDE.md1つに書くと、ファイルが肥大化してClaude Codeが後半を読み飛ばす挙動に近づきます。CLAUDE.mdは「目次と絶対ルール」に絞り、詳細は ~/.claude/rules/*.md などに分割して必要な場面だけ参照する設計が公式でも案内されています。FlatWorksは現在33ファイルに分割しています。
CLAUDE.md は何階層あって、どこに置けばいい?
2026年5月時点の Claude Code 公式仕様では、CLAUDE.md は4階層あります。(1)管理ポリシー(組織配布)、(2)プロジェクト指示(./CLAUDE.md または ./.claude/CLAUDE.md、Git管理向き)、(3)ユーザー指示(~/.claude/CLAUDE.md、個人の全プロジェクト共通)、(4)ローカル指示(./CLAUDE.local.md、gitignore推奨)。読み込み優先順位は「より具体的なスコープが優先」で、Managed → Local → Project → User の順です。個人事業主は (3)+(2) の組み合わせから始めるのが標準です。
サブエージェントとスキル、何が違う?どう使い分ける?
サブエージェント(Subagents)は「役割ごとに独立した人格・ツール権限を持つ別エージェント」です。配置は .claude/agents/ または ~/.claude/agents/。一方スキル(Skills)は「特定のトリガーキーワードで自動起動する専門知識ファイル」で、配置は ~/.claude/skills/<name>/SKILL.md。使い分けは、独立した判断・対話を任せたい場合はサブエージェント、専門知識を必要時だけ読み込ませたい場合はスキルです。FlatWorksでは部署を表現するのにサブエージェント、HP評価などの専門知識をスキルとして両方併用しています。
ファイルが多くなると Claude Code が遅くなる?
「全ファイルを毎回読ませる」設計だと遅くなります。Claude Code は MEMORY.md 等のエントリポイントから始まり、必要なものだけを参照します。(1)CLAUDE.md は目次と絶対ルールに絞る、(2)詳細ルールは rules/*.md に分割し、CLAUDE.md からは必要なものだけ @ 参照、(3)専門知識はスキル化してトリガーで起動、(4)プロジェクト固有情報は projects/<name>/memory/ に閉じ込める、の4点を守れば、ファイル数が増えても重くなりません。
失敗したルールファイルを振り返る仕組みはある?
公式の自動メモリ機能(Auto memory、Claude Code v2.1.59以降)が ~/.claude/projects/<project>/memory/ を読み込みます。FlatWorksではここに feedback_*.md(失敗事例)と reference_*.md(技術リファレンス)を分けて保存し、MEMORY.md を目次にしています。失敗事例を蓄積する習慣をつけると、同じ失敗をAIに繰り返させない運用ができます。最初は1日1件、5分で書く程度で十分です。
最小セットアップは何ファイルから?
FlatWorksの推奨は5ファイルからです。(1)~/.claude/CLAUDE.md(会社概要・絶対ルール・参照先のリンク)、(2)~/.claude/rules/persona.md(口調・人格)、(3)~/.claude/rules/safety_quality.md(やってはいけないこと3点)、(4)~/.claude/projects/<案件>/memory/project_<案件>.md(プロジェクト方針)、(5)~/.claude/projects/<案件>/memory/MEMORY.md(目次)。1日で全部書くのではなく、書きながら運用して、感じた違和感を翌週に追記するのが続けやすいです。
番外編「今更聞けないAIリテラシー入門 — 新入社員にも教えたい『安全なAIの使い方』」
特集記事「AIコーディングツール比較 2026年4月版 — Claude Code / ChatGPT / Copilot / Cursor / Gemini / Codex」
※ 本記事のClaude Code 公式仕様への言及は2026年5月時点の情報です。最新仕様は Claude Code 公式ドキュメント — メモリ管理、 サブエージェント仕様、 スキル仕様 等でご確認ください。FlatWorksのファイル構成・運用例は自社の実例であり、これが唯一の正解というわけではありません。